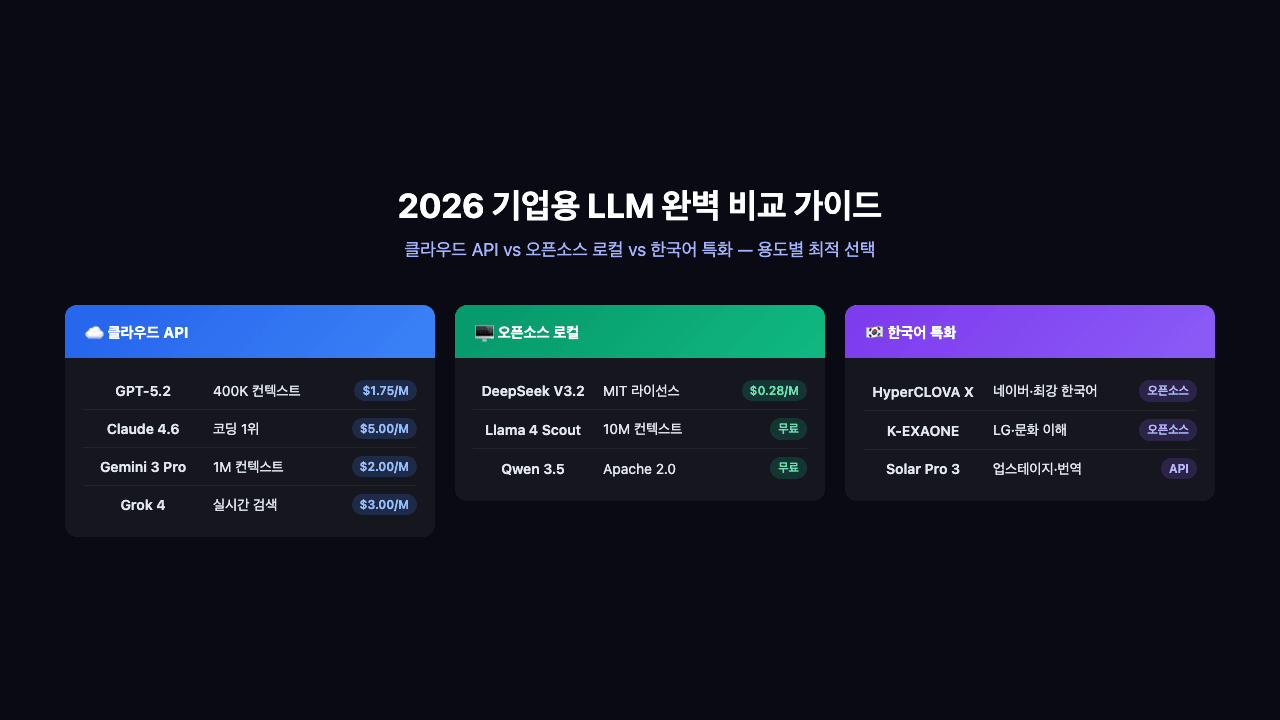
GPT-5.2 vs Claude 4.6 vs Gemini 3 Pro — 2026 기업용 LLM 완벽 비교 가이드
클라우드 API부터 오픈소스 로컬 배포, 한국어 특화 모델까지. 2026년 기업이 선택할 수 있는 모든 LLM을 가격·성능·한국어·보안 4가지 축으로 비교합니다.
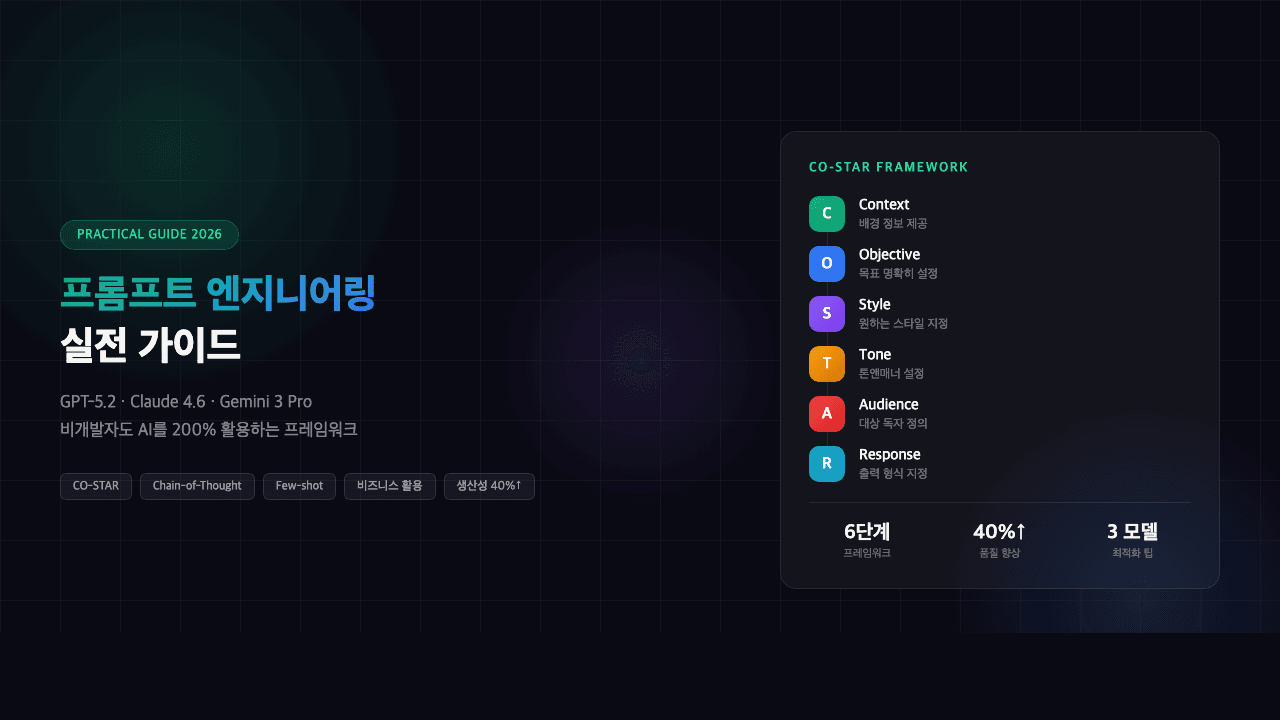
TL;DR
| 목적 | 추천 모델 | 이유 |
|---|---|---|
| 범용 최강 | GPT-5.2 | 400K 컨텍스트, 적응형 추론 |
| 코딩·에이전트 | Claude Opus 4.6 | SWE-Bench 1위, 멀티시간 에이전트 |
| 가성비 최고 | Gemini 3 Pro | 1M 컨텍스트, $2/M 입력 |
| 초저가 API | DeepSeek V3.2 | $0.28/M, GPT-5급 성능 |
| 로컬 배포 | Llama 4 Scout / Qwen 3.5 | 무료, 10M 컨텍스트 |
| 한국어 최강 | HyperCLOVA X SEED | GPT-4 대비 6,500배 한국어 데이터 |
1. 클라우드 API — 빠르게 시작하고 싶다면
GPT-5.2 (OpenAI)
2025년 12월 출시. OpenAI의 최신 플래그십 모델입니다.
- 컨텍스트: 400K 토큰 (출력 128K)
- 핵심 기능: 적응형 연산 — 질문 난이도에 따라 자동으로 처리량 조절. Auto/Instant/Thinking 3가지 모드
- 벤치마크: AIME 2025 수학 100%, GPQA Diamond 93.2%
- 가격: 입력 $1.75/M, 출력 $14.00/M
- Pro 버전: 입력 $21.00/M, 출력 $168.00/M (최고 추론 성능)
적합한 용도: 복잡한 추론, 수학/과학 분석, 대용량 문서 처리
Claude Opus 4.6 (Anthropic)
2026년 2월 출시. 코딩과 에이전트 작업에서 업계 최고입니다.
- 컨텍스트: 200K 표준 / 1M (베타)
- 핵심 기능: SWE-Bench Verified 72.5%(1위), 멀티시간 에이전트 워크플로우, 확장 사고 + 도구 사용
- 가격: 입력 $5.00/M, 출력 $25.00/M
- 배치 할인: 50% (대량 처리 시)
적합한 용도: 코드 생성/리뷰, AI 에이전트 구축, 복잡한 멀티스텝 작업
Gemini 3 Pro (Google)
2025년 11월 출시. 가성비와 멀티모달에서 최강입니다.
- 컨텍스트: 1M 토큰
- 핵심 기능: 텍스트·이미지·비디오·오디오·코드·PDF 모두 처리, MMLU-Pro 89.8%(1위)
- 가격: 입력 $2.00/M, 출력 $12.00/M
- 특장점: 프론티어 모델 중 최고 가성비
적합한 용도: 멀티모달 분석, 대규모 문서 처리, 비용 효율적 범용 활용
Grok 4 (xAI)
2025년 7월 출시. 실시간 검색 통합이 강점입니다.
- 컨텍스트: 256K 토큰
- 핵심 기능: 실시간 웹 검색 통합, 4-에이전트 병렬 협업, Humanity's Last Exam 50%
- 가격: 입력 $3.00/M, 출력 $15.00/M
- Fast 버전: 입력 $0.20/M, 출력 $0.50/M
적합한 용도: 실시간 정보 기반 분석, 리서치 자동화
클라우드 API 가격 비교표
| 모델 | 입력 ($/M) | 출력 ($/M) | 컨텍스트 | 최강 분야 |
|---|---|---|---|---|
| GPT-5.2 | $1.75 | $14.00 | 400K | 추론·범용 |
| GPT-5 Mini | $0.25 | $2.00 | 400K | 경량 작업 |
| GPT-5 Nano | $0.05 | $0.40 | — | 초대량 처리 |
| Claude Opus 4.6 | $5.00 | $25.00 | 1M | 코딩·에이전트 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M | 코딩 가성비 |
| Gemini 3 Pro | $2.00 | $12.00 | 1M | 멀티모달·가성비 |
| Grok 4 | $3.00 | $15.00 | 256K | 실시간 검색 |
| Grok 4 Fast | $0.20 | $0.50 | 256K | 예산형 추론 |
| DeepSeek V3.2 | $0.28 | $0.40 | 164K | 초저가 프론티어 |
2. 오픈소스 로컬 배포 — 데이터를 밖에 보낼 수 없다면
보안 규제, 데이터 주권, 또는 장기 비용 절감을 위해 자체 서버에서 LLM을 운영해야 하는 기업이 늘고 있습니다.
DeepSeek V3.2
2025년 12월 출시. MIT 라이선스로 상업적 사용이 완전히 자유롭습니다.
- 파라미터: 685B 전체 / 37B 활성 (MoE)
- 컨텍스트: 164K 토큰
- 성능: 다수 벤치마크에서 GPT-5를 상회
- GPU 요구사항:
- FP8: H100 80GB × 8대 (
월 8801,800만원) - INT4: H100 × 5대 (
월 5501,100만원)
- FP8: H100 80GB × 8대 (
- 한국어: CJK 최적화로 양호
- 라이선스: MIT — 가장 자유로운 오픈소스 라이선스
⚠️ 중국 기업(DeepSeek) 모델이라 일부 기업에서 데이터 주권 우려가 있을 수 있습니다. 로컬 배포 시에는 데이터가 외부로 나가지 않으므로 실질적 위험은 낮습니다.
Llama 4 Scout (Meta)
2025년 4월 출시. 역대 최장 10M 컨텍스트 윈도우가 특징입니다.
- 파라미터: 109B 전체 / 17B 활성 (16 전문가 MoE)
- 컨텍스트: 10M 토큰 (업계 최장)
- GPU 요구사항:
- FP8: H100 × 2대 (
월 220440만원) - INT4: H100 × 1대 (
월 110220만원)
- FP8: H100 × 2대 (
- 한국어: 공식 지원 12개 언어에 한국어 미포함 — 한국어 성능 약함
- 라이선스: Llama 4 Community License (MAU 7억 이상 시 별도 협의)
Qwen 3.5 (Alibaba)
2026년 2월 출시. Apache 2.0 라이선스에 201개 언어를 지원합니다.
- 파라미터: 397B 전체 / 17B 활성 (MoE)
- 컨텍스트: 250K 토큰
- GPU 요구사항:
- FP8: H100 × 4대 (
월 440880만원) - INT4: RTX 4090 1대로도 가능 (성능 제한)
- FP8: H100 × 4대 (
- 한국어: KMMLU 벤치마크 평가, 201개 언어 지원으로 양호
- 라이선스: Apache 2.0 — 제한 없는 상업적 사용
로컬 배포 비용 비교표
| 모델 | 최소 GPU | 월 비용 (클라우드 GPU) | 한국어 | 라이선스 |
|---|---|---|---|---|
| DeepSeek V3.2 (FP8) | H100 × 8 | 880~1,800만원 | ★★★ | MIT |
| DeepSeek V3.2 (INT4) | H100 × 5 | 550~1,100만원 | ★★★ | MIT |
| Llama 4 Scout (INT4) | H100 × 1 | 110~220만원 | ★★ | Community |
| Qwen 3.5 (FP8) | H100 × 4 | 440~880만원 | ★★★ | Apache 2.0 |
| Qwen 3.5 (INT4) | RTX 4090 × 1 | 22~36만원 | ★★★ | Apache 2.0 |
💡 팁: 클라우드 GPU 대여 시 Lambda Labs($2.99/시간, 8×H100), Vast.ai($1.49/시간), RunPod 등이 경쟁력 있습니다. 장기 계약 시 30-50% 할인도 가능합니다.
3. 한국어 특화 모델 — 한국 기업이라면 주목
범용 모델의 한국어 성능은 영어 대비 여전히 낮습니다. 한국어가 핵심이라면 전용 모델을 고려하세요.
HyperCLOVA X SEED (네이버)
네이버가 공개한 오픈소스 한국어 AI 모델입니다.
- 모델 라인업: Think-32B, Think-14B, Text-1.5B 등 다양한 크기
- 한국어 데이터: GPT-4 대비 6,500배 더 많은 한국어 데이터로 학습
- 핵심 강점: 한국 문화, 사회 규범, 가치관 이해 내장
- GPU: Think-32B는 A100 80GB × 2대 (
월 96114만원) - 라이선스: 오픈소스, 상업적 사용 가능
K-EXAONE (LG AI Research)
2026년 1월 출시. 한국 국가 AI 파운데이션 모델 프로젝트에서 13개 벤치마크 중 10개 1위를 기록했습니다.
- 파라미터: 236B 전체 / 23B 활성 (MoE)
- 컨텍스트: 256K 토큰
- 핵심 강점: 한국 역사·문화 맥락까지 이해하는 깊은 한국어 능력
- GPU: H200 × 4대 (
월 1,0201,460만원) - 글로벌 순위: Artificial Analysis Intelligence Index 세계 7위
EXAONE Deep 32B (LG AI Research)
좀 더 가볍고 경제적인 한국어 추론 모델입니다.
- 파라미터: 32B (Dense)
- 한국어 수능 수학: 94.5점
- GPU: H100 × 1대 (
월 110220만원), 양자화 시 RTX 4090도 가능 - Ollama로 간편 배포 가능
Solar Pro 3 (Upstage)
2026년 1월 출시. 한국어 번역과 자연스러운 표현에서 최고 수준입니다.
- 파라미터: 102B 전체 / 12B 활성 (MoE)
- 핵심 강점: Ko-Arena-Hard-Auto에서 GPT-4를 상회
- 현재 상태: API로 제공 (2026년 3월 2일까지 무료)
- Solar Open 100B: 오픈소스 버전 Hugging Face에서 다운로드 가능
한국어 성능 순위
| 모델 | 한국어 품질 | 특징 |
|---|---|---|
| HyperCLOVA X SEED | ★★★★★ | 한국어 데이터 최다, 문화 이해 |
| K-EXAONE | ★★★★★ | 역사·문화 맥락, 국가 프로젝트 1위 |
| Solar Pro 3 | ★★★★ | 번역 최강, 자연스러운 표현 |
| EXAONE Deep 32B | ★★★★ | 수능 수학 94.5, 추론 강점 |
| DeepSeek V3.2 | ★★★ | CJK 최적화, 양호 |
| Claude 4.6 | ★★★ | 유려한 한국어 표현 |
| Qwen 3.5 | ★★★ | 201개 언어, KMMLU 평가 |
| GPT-5.2 | ★★★ | 전반적 양호 |
| Gemini 3 Pro | ★★★ | 고유명사 정확도 높음 |
| Llama 4 | ★★ | 한국어 공식 미지원 |
4. 배포 방식 선택 가이드
클라우드 API가 적합한 경우
- ✅ 빠른 프로토타입이 필요할 때
- ✅ GPU 인프라 관리 인력이 없을 때
- ✅ 사용량이 불규칙할 때 (종량제 과금)
- ✅ 최신 모델을 항상 사용하고 싶을 때
로컬 배포가 적합한 경우
- ✅ 금융·의료·공공 등 데이터가 외부로 나갈 수 없을 때
- ✅ 월 API 비용이 GPU 서버 비용을 초과할 때 (대량 처리)
- ✅ 모델 커스터마이징(파인튜닝)이 필요할 때
- ✅ 네트워크 지연 없는 실시간 응답이 필요할 때
하이브리드 전략 (추천)
많은 기업이 두 가지를 병행합니다:
- 일반 업무: 클라우드 API (GPT-5.2, Gemini 3 Pro)
- 민감 데이터: 로컬 오픈소스 (DeepSeek V3.2, HyperCLOVA X)
- 한국어 특화: 한국어 모델 (K-EXAONE, Solar Pro 3)
LLM 게이트웨이를 두고 용도별로 라우팅하는 것이 가장 효율적입니다.
5. 로컬 배포 실전 — 어떻게 구축하나?
추천 기술 스택
| 레이어 | 도구 | 역할 |
|---|---|---|
| 추론 엔진 | vLLM v0.16 | 고성능 모델 서빙 |
| 컨테이너 | Kubernetes + GPU Operator | 오케스트레이션 |
| 게이트웨이 | LiteLLM / OpenRouter | API 라우팅·로드밸런싱 |
| 모니터링 | OpenTelemetry | 추적·로깅·메트릭 |
| 보안 | RBAC + 감사 로그 | 접근 제어·컴플라이언스 |
vLLM v0.16 (2026년 2월)
가장 많이 사용되는 오픈소스 LLM 추론 엔진입니다.
- 비동기 스케줄링으로 30.8% 처리량 향상
- FP8, FP4, INT4 양자화 지원
- NVIDIA H100/H200, AMD MI300X, Intel Gaudi 3 지원
- DeepSeek Sparse Attention 최적화 커널 내장
Ollama
개발자 프로토타이핑과 소규모 팀에 적합합니다.
- 데스크톱 앱 (macOS/Windows)
ollama run llama4한 줄로 실행- 멀티 GPU 파이프라인 병렬 처리
- NPU 가속 지원 (노트북/엣지)
6. 시나리오별 추천 조합
시나리오 A: 스타트업 (예산 최소화)
| 용도 | 모델 | 월 비용 |
|---|---|---|
| 주력 | Gemini 3 Pro API | 사용량 기반 |
| 백업 | GPT-5 Nano API | $0.05/M |
| 한국어 | Solar Pro 3 API (무료 체험) | 무료 |
시나리오 B: 중견기업 (보안 중요)
| 용도 | 모델 | 월 비용 |
|---|---|---|
| 일반 업무 | Claude Sonnet 4.6 API | 사용량 기반 |
| 민감 데이터 | EXAONE Deep 32B (로컬) | ~150만원 |
| 한국어 CS | HyperCLOVA X SEED-32B (로컬) | ~100만원 |
시나리오 C: 대기업 (풀스택)
| 용도 | 모델 | 월 비용 |
|---|---|---|
| 고급 추론 | GPT-5.2 API | 사용량 기반 |
| 코딩·에이전트 | Claude Opus 4.6 API | 사용량 기반 |
| 데이터 분석 | DeepSeek V3.2 (로컬) | ~1,000만원 |
| 한국어 특화 | K-EXAONE (로컬) | ~1,200만원 |
마무리
2026년 LLM 시장은 클라우드 API의 편의성, 오픈소스의 자유도, 한국어 특화 모델의 품질이 모두 극적으로 향상되었습니다.
핵심 메시지 3가지:
- "하나만 쓰자"는 틀린 전략입니다. 용도별로 최적 모델을 조합하세요.
- 한국어가 중요하면 한국어 모델을 쓰세요. HyperCLOVA X, K-EXAONE은 GPT-5보다 한국어가 뛰어납니다.
- 로컬 배포는 더 이상 어렵지 않습니다. vLLM + Ollama로 하루 만에 구축 가능합니다.
어떤 모델이 우리 회사에 맞는지 고민되시나요? RunAI는 기업 환경에 최적화된 LLM 선정부터 구축까지 도와드립니다.
이 글은 2026년 2월 기준 정보입니다. LLM 시장은 빠르게 변하므로, 도입 시점에 최신 벤치마크와 가격을 다시 확인하시기 바랍니다.